
Description
This article explains the steps you need to take to deploy a high availability kubernetes cluster in your environment. This cluster will comprise of 3 control nodes and 3 worker nodes. We will not dive into the details and concepts behind the differences between the control plane nodes and worker nodes but these are some responsibilities of each:
- Control nodes modules
- kube-apiserver – the interface through which the cluster is controlled
- etcd – data store for the cluster state
- stacked – collocated within the control node
- external
- scheduler – assigns newly created pods to nodes
- controller-manager – runs specific controllers( logic ) for checking nodes, executing tasks, etc
- Worker nodes modules
- dns addon – dns resolution for pods and services
- Common modules
- kube-proxy – maintains network rules
- kubelet – checks if containers are running inside the pod
Getting started
The following image shows the connection diagram between nodes and the inner-connections between modules. We will have to add some parts but most of the heavy lifting is done through the kubernetes tool kubeadm.
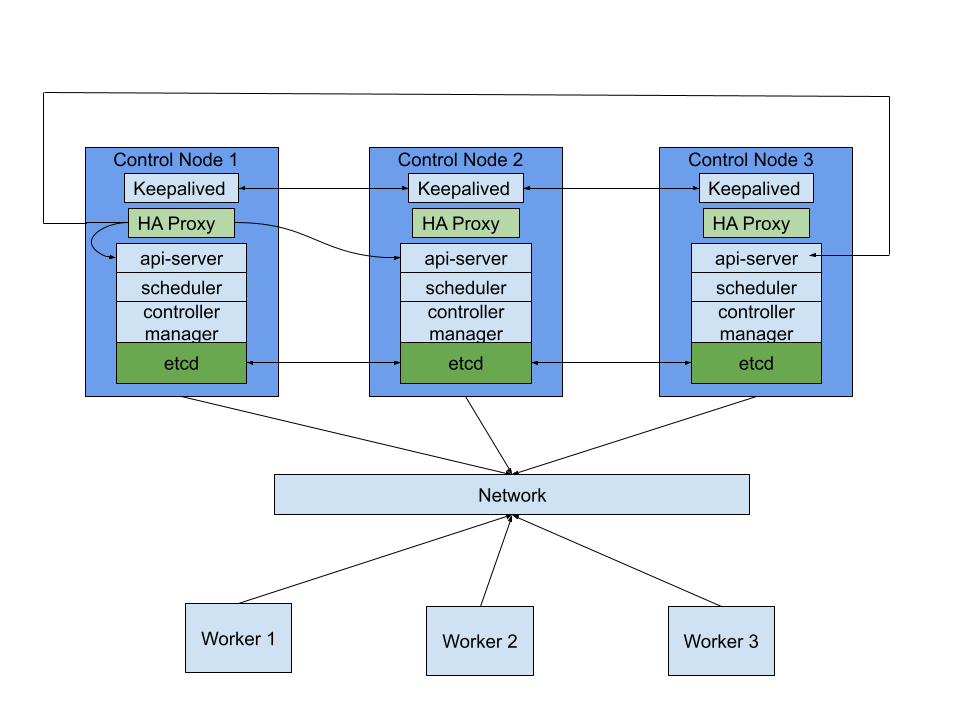
Hardware:
- 6 hosts with Ubuntu 22.04
- 3 control hosts 2 cores, 2GB RAM( at least )
- 3 worker hosts 2 cores, 2GB RAM( at least )
Steps:
- Prepare systems
- update package list, install needed packages
- disable swap( k8s prerequisite )
- Configure high availability for master nodes
- configure failover with keepalived
- configure http balancing
- Configure kubernetes for nodes
- configure master nodes
- configure worker nodes
- Test
Prepare systems
This stage should be performed 6 times for each of the cluster nodes( masters and workers ). You could speed up this process by having a VM template or a disk image of an already configured system.
# set hostname !! replace hostname on each node
k8suser@master-1:~$ sudo hostnamectl set-hostname "master-1"
# start new bash
k8suser@master-1:~$ exec bash
# update package list
k8suser@master-1:~$ sudo apt update
# upgrade installed packages
k8suser@master-1:~$ sudo apt upgrade
# disable swap
k8suser@master-1:~$ sudo swapoff -a
# after this /proc/swaps should be empty
k8suser@master-1:~$ cat /proc/swaps
Filename Type Size Used PriorityOpen /etc/fstab and make sure that no line with filesystem type “swap” exists:
UUID=30507c9c-18b0-41c2-a331-95f8af945a27 none swap sw 0 0 # <--- delete or comment
/swap.img none swap sw 0 0 # <---- delete or commentEnable ipv4 forwarding and bridged traffic:
# forwarding IPv4 and letting iptables see bridged traffic
k8suser@master-1:~$ cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
k8suser@master-1:~$ sudo modprobe overlay br_netfilter
# Persist parameters across reboots
k8suser@master-1:~$ cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# Apply sysctl params without reboot
k8suser@master-1:~$ sudo sysctl --systemInstall the containerd runtime :
k8suser@master-1:~$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
k8suser@master-1:~$ echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
k8suser@master-1:~$ sudo apt update
k8suser@master-1:~$ sudo apt install containerd.io
# generate a default config and write it to the default location
k8suser@master-1:~$ containerd config default | sudo tee /etc/containerd/config.toml >/dev/null 2>&1
# use systemd as the cgroup manager
k8suser@master-1:~$ sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
# use same sandbox as kubernetes tools
k8suser@master-1:~$ sudo sed -i 's/sandbox_image = "registry.k8s.io\/pause:3.6"/sandbox_image = "registry.k8s.io\/pause:3.9"/g' /etc/containerd/config.toml
# restart containerd
k8suser@master-1:~$ sudo systemctl restart containerdInstall kubernetes tools:
# trust kubernetes repo key, we'll use xenial, newer repo may be used
k8suser@master-1:~$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/kubernetes-xenial.gpg
# add repo
k8suser@master-1:~$ sudo apt-add-repository "deb http://apt.kubernetes.io/ kubernetes-xenial main"
k8suser@master-1:~$ sudo apt install kubeadm kubelet kubectl kubernetes-cniConfigure high availability for master nodes
By completing this stage you will make sure that fail-over and load balancing are configured for the control plane. Next steps should be performed only on the master nodes, that is 3 times for our example.
If we analyse the proposed topology again, we will see that our cluster state is held and proxied by the master nodes. One question that arises is what happens if one of the nodes disappears. We will mitigate this issue by using keepalived. One of the nodes will start as a master and will take a VIP address( a designated address ) and set it to its interface. If it goes down for some reason the backup node with the highest priority will become master and set the VIP address to the selected interface.
k8suser@master-1:~$ sudo mkdir /etc/keepalived
k8suser@master-1:~$ sudo vim /etc/keepalived/keepalived.conf! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state ${STATE}
interface ${INTERFACE}
virtual_router_id ${ROUTER_ID}
priority ${PRIORITY}
authentication {
auth_type PASS
auth_pass ${AUTH_PASS}
}
virtual_ipaddress {
${APISERVER_VIP}
}
track_script {
check_apiserver
}
}Replace placeholders with:
- ${STATE} – MASTER on the default master and BACKUP on the other 2
- ${INTERFACE} – enp0s3 or any other interface on the same network segment as the others nodes
- ${ROUTER_ID} – any number, must be the same on all nodes
- ${PRIORITY} – any number, determines the selection priority for the next master
- ${AUTH_PASS} – a common password for all nodes
- ${APISERVER_VIP} – the VIP address that will be used to access the API Server through kubectl
Add the health status script used by the configuration.
k8suser@master-1:~$ sudo vim /etc/keepalived/check_apiserver.sh#!/bin/sh
# !!!! change below values !!!
APISERVER_DEST_PORT="8443"
APISERVER_VIP="192.168.0.60"
errorExit() {
echo "*** $*" 1>&2
exit 1
}
curl --silent --max-time 2 --insecure https://localhost:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://localhost:${APISERVER_DEST_PORT}/"
if ip addr | grep -q ${APISERVER_VIP}; then
curl --silent --max-time 2 --insecure https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/"
fi
Next we will balance between the API Servers with a round-robin logic through haproxy.
k8suser@master-1:~$ sudo mkdir /etc/haproxy
k8suser@master-1:~$ sudo vim /etc/haproxy/haproxy.cfg#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log /dev/log local0
log /dev/log local1 notice
daemon
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 1
timeout http-request 10s
timeout queue 20s
timeout connect 5s
timeout client 20s
timeout server 20s
timeout http-keep-alive 10s
timeout check 10s
#---------------------------------------------------------------------
# apiserver frontend which proxys to the control plane nodes
#---------------------------------------------------------------------
frontend apiserver
bind *:${APISERVER_DEST_PORT}
mode tcp
option tcplog
default_backend apiserver
#---------------------------------------------------------------------
# round robin balancing for apiserver
#---------------------------------------------------------------------
backend apiserver
option httpchk GET /healthz
http-check expect status 200
mode tcp
option ssl-hello-chk
balance roundrobin
server ${HOST1_ID} ${HOST1_ADDRESS}:${APISERVER_SRC_PORT} check
# modify the configuration as you add more nodes
# [...]- ${APISERVER_DEST_PORT} – the VIP port – ex.: 8443
- ${APISERVER_SRC_PORT} – API Server port – ex.: 6443
- ${HOST1_ID} – a node id for the server – ex: master-1
- ${HOST1_ADDRESS} – the real address of the server
- should look like:
- server master-1 192.168.0.50:6443 check
- server master-2 192.168.0.51:6443 check
- server master-3 192.168.0.52:6443 check
keepalived and haproxy configurations are in place and we need to start using them. To start these daemons we will rely on kubelet. Kubelet will manage their lifecycle and will start them because we define them in the /etc/kubernetes/manifests folder.
k8suser@master-1:~$ sudo vim /etc/kubernetes/manifests/keepalived.yaml---
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: keepalived
namespace: kube-system
spec:
containers:
- image: osixia/keepalived:2.0.17
name: keepalived
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
- NET_BROADCAST
- NET_RAW
volumeMounts:
- mountPath: /usr/local/etc/keepalived/keepalived.conf
name: config
- mountPath: /etc/keepalived/check_apiserver.sh
name: check
hostNetwork: true
volumes:
- hostPath:
path: /etc/keepalived/keepalived.conf
name: config
- hostPath:
path: /etc/keepalived/check_apiserver.sh
name: check
status: {}k8suser@master-1:~$ sudo vim /etc/kubernetes/manifests/haproxy.yaml---
apiVersion: v1
kind: Pod
metadata:
name: haproxy
namespace: kube-system
spec:
containers:
- image: haproxy:2.1.4
name: haproxy
livenessProbe:
failureThreshold: 8
httpGet:
host: localhost
path: /healthz
port: 8443
scheme: HTTPS
volumeMounts:
- mountPath: /usr/local/etc/haproxy/haproxy.cfg
name: haproxyconf
readOnly: true
hostNetwork: true
volumes:
- hostPath:
path: /etc/haproxy/haproxy.cfg
type: FileOrCreate
name: haproxyconf
status: {}# set a FQDN for our VIP
k8suser@master-1:~$ sudo vim /etc/hosts
192.168.0.60 cluster-1.flobinsa.com
# on master-1 !!!
k8suser@master-1:~$ sudo kubeadm init --control-plane-endpoint cluster-1.flobinsa.com:8443 --pod-network-cidr 10.244.0.0/16 --upload-certs
k8suser@master-1:~$ mkdir -p $HOME/.kube
k8suser@master-1:~$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
k8suser@master-1:~$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
# configure network
k8suser@master-1:~$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# check node status
k8suser@master-1:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master-1 Ready control-plane 6m4s v1.27.1
# on master-2, master-3 !!! Parameters are to be taken from the output of the previous command
k8suser@master-1:~$ kubeadm join cluster-1.flobinsa.com:8443 --token ${token}
--discovery-token-ca-cert-hash ${cert-hash}
--control-plane --certificate-key ${cert-key}To join worker nodes we need to follow all the steps in the preparation stage and issue the join command.
# on worker-1, worker-2, worker-3 !!! Parameters are to be taken from the output of the master initialization
kubeadm join cluster-1.flobinsa.com:8443 --token ${token}
--discovery-token-ca-cert-hash ${cert-hash}Test
k8suser@master-1:~$ kubectl get nodes